
Generative AI for text to image is a revolutionary technology that allows users to create images based on text descriptions. This technology combines artificial intelligence and machine learning to generate visual content that matches the given text input.
The importance of technology in image creation:
- Efficiency: Reduces time and effort in the design process.
- Creativity: Opens up new opportunities for artists and designers to explore innovative ideas.
- Accessibility: Enables individuals without design skills to create high-quality images.
Recent developments in AI and digital art show significant improvements in the capabilities of generative models. Models like DALL-E, Midjourney, and Photosonic have introduced new ways to create digital artwork, ranging from illustrations to marketing mockups.
Read More:
Elevate your business potential with Kata.ai powerful generative AI platform. Build enterprise-scale bots easily, integrate seamlessly with messaging services, and leverage robust natural language understanding. Achieve unparalleled customer satisfaction and operational efficiency with our AI-driven solutions.
The use of generative AI continues to expand across various fields, making it a vital tool in the modern creative world.
What is Generative AI for Text to Image?
Generative AI is a technology of artificial intelligence that is capable of creating new content, such as images or text, based on previously trained data. In the context of text-to-image, generative AI allows users to create images simply by providing a text description. This technology uses advanced machine learning models that can understand and interpret text input to generate corresponding visual content.
How Multimodal Models Work in Text Interpretation
Multimodal models are a type of AI model that can process and connect different types of data, such as text and images. In the process of text-to-image generation, multimodal models play an important role in the following ways:
- Describing Text Description: The model will understand the text description provided by the user. For example, if you provide the description “a white cat sitting on a red sofa,” the model will break down this sentence into important elements such as “white cat,” “red sofa,” and “sitting.”
- Connecting Text with Visual Representation: After the text is analyzed, the multimodal model will match those elements with relevant visual representations. This involves using a large database containing images and related information.
Process of Creating Images Based on Text Description
The process of creating images from text descriptions goes through several main stages:
- Text Input: The user enters a text description into the system.
- Text Processing: The multimodal model analyzes and understands the description.
- Image Generation: Based on its understanding of the text, the model then generates a corresponding image.
Practical examples of this process can be seen on platforms like DALL-E 2 or Midjourney. You just need to enter a simple description like “a futuristic city at night” and the system will generate several variations of images that match that description.
Generative AI technology for text-to-image opens up many creative opportunities for various industries, ranging from digital art to visual marketing. In addition, the application of this technology is also in line with global trends in the use of advanced technology to support education, where generative AI can be used to create more interactive and engaging teaching materials.
The Technology Behind Text-to-Image Generation
Neural Networks and Their Role in Generating Images
Artificial neural networks are the backbone of generative AI technology. By using architectures that mimic the way the human brain works, these neural networks are able to learn from data and make predictions or generate new content. In text-based image generation, neural networks are used to understand text descriptions and convert them into corresponding visual images.
Deep Learning in Image Generation
Deep learning is a machine learning technique that involves the use of multiple layers of neural networks to process information. This technique is highly effective in image generation because it can capture intricate details from input data. Deep learning models are trained with large datasets containing pairs of text and images, allowing them to learn the correlation between text descriptions and visual elements.
Diffusion Models and Autoregressive Models
Diffusion models are a type of generative model that work by gradually refining images through a series of steps. These models start with random images and then undergo step-by-step processing until they produce a final image that matches the text description. The advantages of diffusion models include their ability to generate high-quality images with fine details.
On the other hand, autoregressive models work by predicting the next pixel based on the previous pixels, one by one until the entire image is formed. This approach allows for more detailed control over the image generation process, but often requires longer computation time compared to diffusion models.
Read More: What is Generative AI?
Advantages of Each Model
Diffusion Models:
- Sble to generate images with fine details.
- The iterative process allows for gradual improvements.
- Tend to be efficient in the use of computational resources.
Autoregressive Models:
- Provide more detailed control over each part of the image.
- The final result is usually very accurate according to the text description.
- Suitable for applications where high precision is required.
The use of both models provides flexibility in various text-to-image generation applications, allowing users to choose the approach that best suits their specific needs. In addition, this technology also has great potential in educational AI, opening up new opportunities in the way we learn and teach.
Popular Platforms for Text-to-Image Generation
1. DALL-E 2
Developed by OpenAI, DALL-E 2 is one of the most well-known generative AI platforms for text to image. Some key features of DALL-E 2 include:
- The ability to generate high-quality images from complex text descriptions.
- Visual style variation: DALL-E 2 can generate images in various styles, ranging from realistic to abstract.
- Content flexibility: Users can input specific details such as mood, color, and elements in the image.
An example of using DALL-E 2 in creative projects is the creation of illustrations for children’s books. By entering a description such as “a blue cat wearing a red hat playing in the garden,” DALL-E 2 can create images according to the writer’s imagination.
2. Midjourney
Midjourney is another well-known platform in the field of generative AI for text to image. Midjourney uses advanced neural network models to interpret text and generate images. The way Midjourney works involves:
- Text analysis: Understanding the text description in depth to capture its nuances and details.
- Image generation: Using deep learning models to create accurate visuals based on that description.
Midjourney is often used by digital artists and graphic designers to create unique artworks without the need for manual drawing skills.
3. Photosonic
Photosonic stands out with its features that differ from other platforms. Some features of Photosonic include:
- Wide range of style options: Photosonic offers various artistic styles ranging from modern to classic.
- Advanced editing capabilities: After the images are generated, users can perform further editing directly on the platform.
- Easy integration: Photosonic integrates with other design tools, making the creative process easier.
Photosonic is often used in marketing and digital content projects where speed and visual quality are essential.
Generative AI for text to image is rapidly evolving, providing advanced tools that allow anyone, whether professionals or beginners, to create attractive visuals with just simple text input.
Comparison of the Best Text-to-Image Tools
Choosing the best AI text-to-image tool requires consideration of several important criteria. Some factors to consider include:
- Image Quality: How well the tool generates realistic images that match the text description.
- Ease of Use: An intuitive and easy-to-understand user interface is very important, especially for beginners.
- Generation Speed: The time it takes to generate an image from a text description.
- Flexibility and Customization: The ability to customize parameters and styles of images to suit specific needs.
- Price: The level of cost or subscription packages offered.
Feature Comparison Table
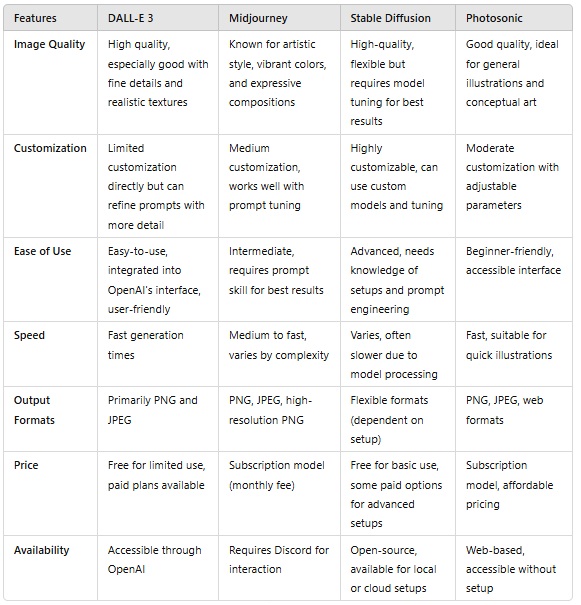
DALL-E 3
Advantages:
- Natural Language Understanding: DALL-E 3 excels in understanding complex and nuanced prompts, allowing it to generate images that closely match detailed descriptions.
- Flexibility: DALL-E 3 can work well in various styles and subjects, making it suitable for diverse creative needs.
- Integration: As part of the OpenAI ecosystem, DALL-E 3 integrates well with other AI tools and services, providing a smoother user experience.
Limitations:
- Style Consistency: Although DALL-E 3 is versatile, it may not always maintain style consistency across different image generations, especially for highly stylized or artistic images.
- Artistic Precision: Midjourney may still produce more artistically refined images, especially when a specific art style or high detail is required.
Midjourney
Advantages:
- Artistic and Stylish Images: Midjourney is known for producing highly stylish and artistic images, which often have a more “mature” or professional look. This makes it very popular among artists and designers.
- Style Customization: Midjourney allows for more detailed customization of artistic styles, making it the top choice for users looking for very specific visual aesthetics.
Limitations:
- Prompt Flexibility: Although Midjourney creates beautiful images, it may require more specific prompts to achieve the desired results, especially for complex or abstract concepts.
- Generalization: Midjourney may not be as flexible as DALL-E 3 in handling various topics, especially those that are more conceptual or require a deep understanding of context.
Stable Diffusion
Advantages:
- Open Source: Stable Diffusion is a highly flexible open-source tool that allows users to customize the model according to their needs.
- Image Quality: Capable of producing very realistic images with good detail, especially for landscapes, portraits, and complex scenes.
- Community and Support: Strong community support with various downloadable modifications and models, offering flexibility in usage.
Disadvantages:
- Difficulty of Use: Requires more technical knowledge for setup and optimization compared to other tools.
- Consistency: Consistency of results can vary depending on the settings and data used.
Photosonic
Advantages:
- Ease of Use: Designed with a user-friendly interface, it makes it easy for anyone to get started without requiring much technical knowledge.
- Generation Speed: Photosonic is known for quickly generating images, making it ideal for instant use.
- Cost: It offers both free and premium options, making it accessible to various user groups.
Disadvantages:
- Image Quality: Although quite good, the image quality of Photosonic may not compare to DALL-E 3 or Midjourney, especially for more artistic and stylized images.
- Limited Flexibility: Photosonic may not have the flexibility and customization capabilities like Stable Diffusion or Midjourney.
Read More: Understanding Generative AI Text to Image Tool
Practical Applications of Generative AI in Various Fields
Creative Content and Digital Art
Generative AI has opened up new opportunities in the creative industry, especially in content creation and digital art. You can use tools like DALL-E 2 or Midjourney to create illustrations, concept art, and graphic designs simply by entering a text description. For example, a designer can generate various character concepts for video games or film storyboards without the need for manual drawing.
Some practical applications include:
- Children’s Book Illustration: Using text descriptions from stories to create engaging illustrations.
- Product Design: Creating product mockups with various design variations based on text specifications.
- Conceptual Art: Developing initial ideas for large art projects.
Visual Mockups in Marketing
In the field of marketing, generative AI is used to create visual mockups that help marketing teams convey their ideas more effectively. Tools like Photosonic facilitate this process by transforming text descriptions into high-quality images that can be used in presentations, advertisements, and social media content.
Examples of use in marketing:
- Digital Advertising Campaigns: Creating visuals for campaigns that align with the theme and message of the advertisement.
- Client Presentations: Generating more realistic product or service mockups to present to clients.
- Social Media Content: Providing attractive visuals that can increase engagement on social media platforms.
With this capability, generative AI not only speeds up the creative process but also allows for more concrete and engaging visualization of ideas.
Using Text-Based Image Generators for Beginners
Generative AI technology has opened up new opportunities in creating images based on text descriptions. Here is a step-by-step guide to using some popular and beginner-friendly text-based image generator tools.
Midjourney
Midjourney is known for its ability to generate artistic images from text. Here’s how to use it:
- Account Registration: Visit the Midjourney website and create an account.
- Enter Text Prompt: After logging in, you will see a field to enter a text description. For example, “scenic view with mountains and rivers”.
- Additional Settings: Customize settings such as art style or dominant color.
- Generate: Click the generate button to start the image creation process.
- Download: Once finished, download the generated image.
DALL-E 3
DALL-E 3, developed by OpenAI, offers advanced features with a simple interface:
- Create an Account: Sign up on the OpenAI website or a platform that supports DALL-E 3.
- Input Description: Enter a text description in the provided box, for example “a cat playing with a ball”.
- Select Image Preferences: Specify preferences such as image resolution and format.
- Generate Image: Press the generate button and wait a few seconds until the image is created.
- Save the Result: Save the image to your computer.
Copilot Designer by Microsoft Bing
Copilot Designer from Microsoft Bing uses advanced AI models to generate high-quality images:
- Access the Platform: Open Microsoft Bing and find Copilot Designer.
- Describe Your Image: Type a detailed description of the image you want to create, for example “modern logo design with blue color”.
- Customize Output: Adjust parameters such as mood, color, and design style according to your needs.
- Click Generate: Click the generate button to start the image creation process.
- Download Image: After completion, download the result in the desired format.
Canva
Canva offers an easy-to-use AI image generator tool for beginners:
- Sign Up/Login to Canva: Access the Canva website and log in or sign up if you don’t have an account yet.
- Start a New Project: Choose the option to create a new project and select a blank template or a suitable template.
- Use the AI Image Generator:
- Select the AI image generator feature in the sidebar.
- Enter a text description like “illustration of a futuristic city at night”.
- Customize the Results: After the image appears, you can add additional elements or edit it as desired.
- Save or Share: Save your project or share it directly on social media.
Adobe Firefly
Adobe Firefly allows users to quickly create images through text prompts:
- Open Adobe Firefly: Access the Adobe Firefly platform from your browser.
- Enter Text Prompt:
- On the homepage, enter a text description like “portrait of a woman with a background of flowers”.
- Refine the Image:
- Select from several displayed result options.
- Further refine by changing small details if necessary.
- Save Your Project: Download the final results or save directly to Adobe Creative Cloud if you are using other Adobe products.
This text-based image creation tool is designed to make it easy for anyone—including beginners—to create visuals without the need for a deep background in graphic design.
By using one of the tools above, you can start exploring your creative potential in digital art through generative AI for text to image without complex technical obstacles.
Understanding the Features of AI Generative Tools and the Prices They Offer
Common Features of Text-to-Image AI Tools
Generative AI tools for text-to-image offer a variety of features that make it easier for users to create images from text descriptions. Some common features include:
- Prompt-based generation: Users simply enter a text description, and the tool will generate an image according to that description.
- Customization Options: Many platforms allow further customization such as setting the style, color, and mood of the image.
- High-resolution output: Some tools are capable of producing high-resolution images suitable for professional purposes.
- Variety of styles: Support for various styles of images such as realism, cartoon, anime, and more.
- Batch processing: Ability to create multiple images at once from one prompt or several different prompts.
- User-friendly interface: Intuitive interface that is easy to use for everyone, including those without a design background.
Elevate your customer experience to new heights with Kata.ai cutting-edge generative AI technology. Our platform enables businesses to build enterprise-scale bots that offer comprehensive support, from answering complex queries to facilitating smooth transactions. With advanced features like sentiment analysis and multi-language support, our GenAI chatbots provide tailored interactions that boost customer engagement and loyalty. Integrate effortlessly with popular messaging services and enjoy powerful analytics to continuously optimize your AI-driven customer service strategy.
Conclusion
Generative AI for text to image provides many benefits, including the ability to generate high-quality images from text descriptions. This technology facilitates the creative process in various fields such as marketing, digital art, and content creation.
The future potential of generative AI is immense. With the development of increasingly sophisticated AI models, the quality and accuracy of the generated images will continue to improve. Users can expect more innovative features and enhanced performance from generative AI tools in the future.
Summary of generative AI text to image:
- Facilitates image creation without design skills
- Contributes to efficiency and creativity in various industries
- Potential for innovation continues to grow with advancements in AI technology
Trackbacks/Pingbacks